
Msc thesis, UZH, 2025. Supervisor: Prof. Dr. Manuel Günther, Dr. André Anjos, Dr. Olivier Pallanca.
Overview
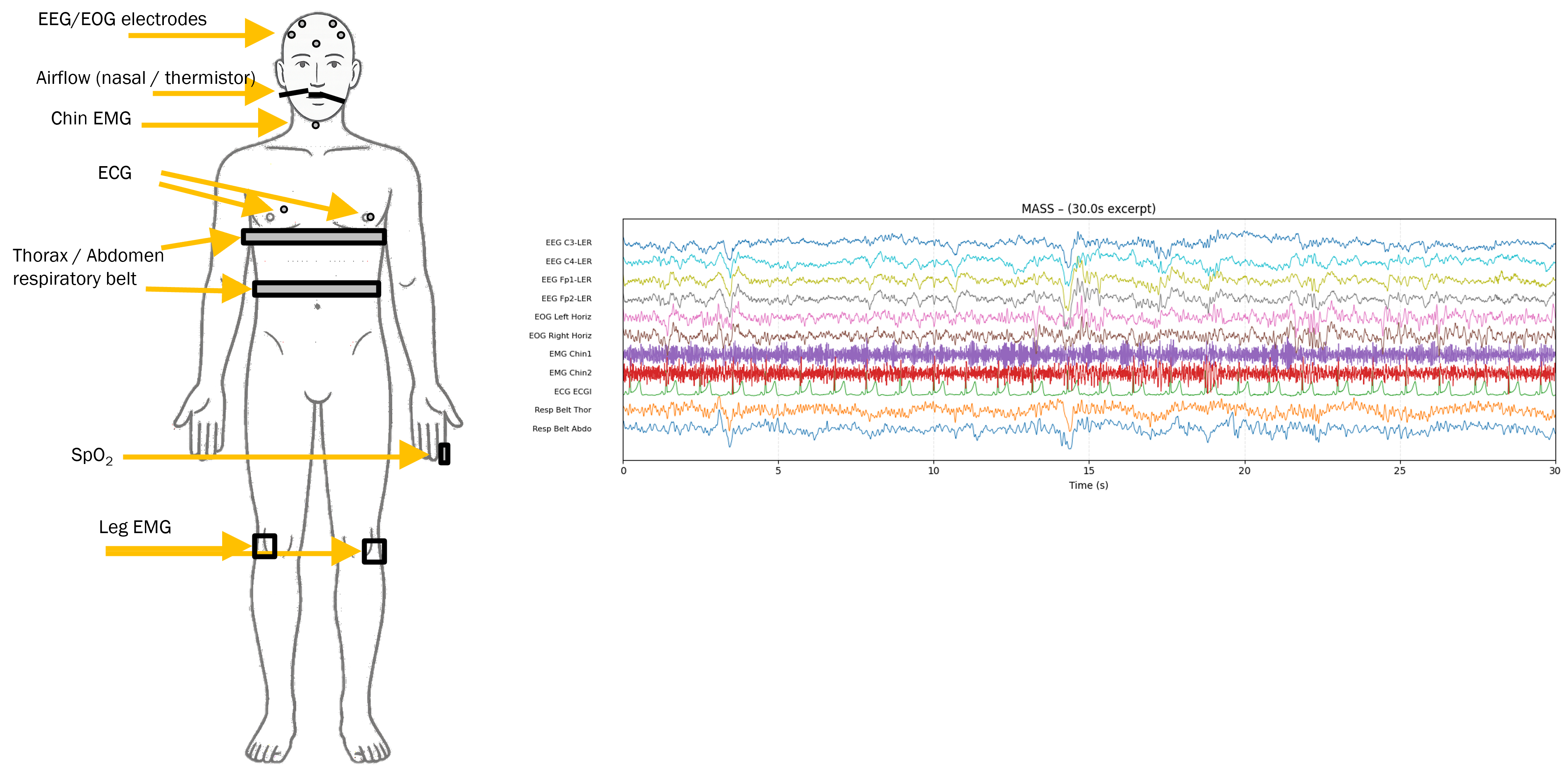
Polysomnography (PSG) is the gold-standard recording for diagnosing sleep disorders - a synchronized capture of EEG, EOG, EMG, ECG, and respiratory signals across an overnight study. Two clinical questions dominate the downstream use of PSG: sleep staging (assigning each 30-second epoch to one of Wake / N1 / N2 / N3 / REM) and sleep apnea detection (identifying breathing events and summarizing their severity via the apnea–hypopnea index, AHI).
Models trained on a single cohort generalize poorly. Recording montages, sampling rates, label conventions, and patient populations differ between sleep labs, so a model that works on one dataset often collapses on another. This thesis asks how far a single contrastively-pretrained Transformer encoder can be pushed as a foundation model for PSG - pretrain once on heterogeneous data, then reuse the frozen encoder for many downstream tasks.
The work builds on the SleepFM set-then-sequence architecture of Thapa et al. (2025) and reproduces, extends, and stress-tests it across five research questions covering pretraining scale, transfer learning, class imbalance, modality contributions, and pretraining objectives.
| Pretraining | 10 public cohorts, ~13,000 subjects, ~121,000 PSG hours, multimodal (BAS + EKG + EMG + RESP), unlabeled |
| Evaluation | SHHS (5,793 subjects, 48,861 hours), held out - never used during pretraining |
| Sleep staging | 76.2% balanced accuracy on SHHS (frozen FM + LSTM), vs. 37.2% for the same LSTM trained from scratch |
| Apnea detection | 75.4% respiratory-event classification BA, vs. 60.4% scratch baseline; AHI severity still favors scratch |
| Headline finding | Frozen multimodal foundation embeddings more than double F1 and balanced accuracy on sleep staging compared to an identical LSTM trained from scratch on the same BAS inputs |
Motivation
A few things attracted me to this problem:
- ·PSG is structurally interesting. The signals span very different time scales - sleep spindles last 0.5–2 s, sleep stages last several minutes, and ultradian cycles take ~90 min. Different physiological signals (brain vs. heart vs. respiration) carry complementary information that a model has to fuse. This is a clean setting to study multimodal sequence modeling without leaving the well-defined evaluation protocols of clinical sleep medicine.
- ·Labels are noisy. Two trained human scorers disagree on 10–20% of epochs. Any model that hits the inter-rater ceiling is, in a real sense, as good as a human. That makes label efficiency and self-supervision particularly attractive.
- ·Foundation-model framing is novel here. Most prior PSG models were single-cohort, single-task, fully supervised. The recent work of SleepFM (Thapa et al., 2024, 2025) showed that contrastive pretraining across cohorts scales, but left open how much data is actually needed, which modalities matter for which task, and how to handle structurally incomplete cohorts. Those are the questions this thesis investigates.
Rather than chasing the largest model, the goal was to understand the foundation-model recipe: where the gains come from, when they saturate, and what fails.
Technical Approach
The signal pipeline
Each PSG recording is broken into 30-second epochs (AASM standard). Each epoch is further split into non-overlapping 5-second patches at 128 Hz, so samples per patch and patches per epoch. For a batch of recordings with channels and samples, the input tensor has shape .
The four modality groups used throughout:
where BAS (Brain Activity Signals) bundles EEG and EOG. A binary channel mask tracks which channels are present per recording, so cohorts with missing modalities can still flow through the same encoder.
Set-then-sequence encoder
The backbone is a set-then-sequence Transformer following SleepFM (Thapa et al., 2025). The key idea: within each patch, channels are treated as an unordered set (permutation-invariant pooling, no positional encoding across channels); across patches, the resulting fused tokens form an ordered sequence (with sinusoidal temporal positional encoding).
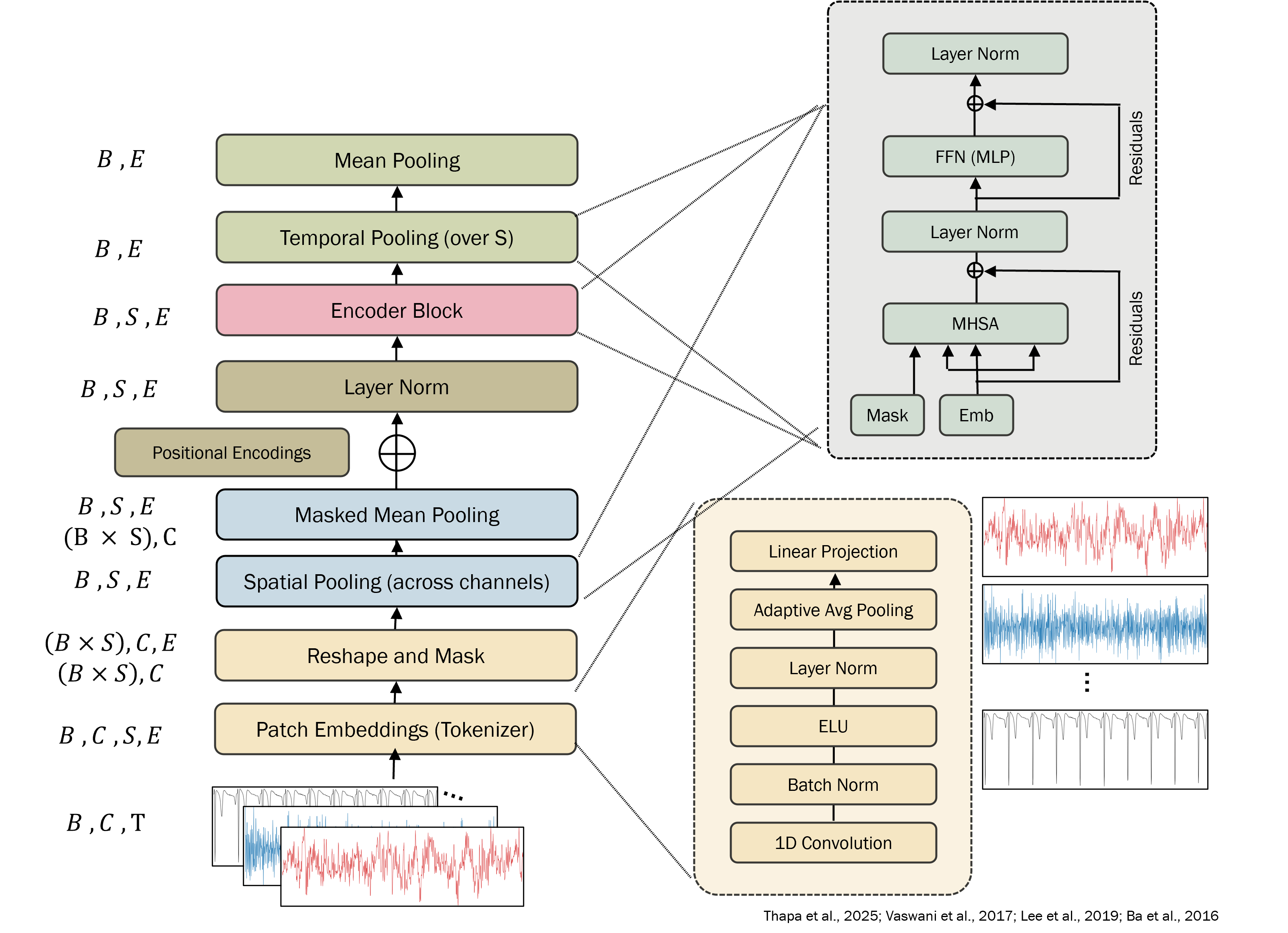
The channel-set encoder is a single Transformer encoder layer applied across the channel tokens within each patch, followed by masked mean pooling that averages only over present channels. Because there's no positional encoding across the channel dimension, the fused token is invariant to the order of channels - which means a model trained on one cohort's channel ordering transfers cleanly to another.
The temporal encoder has layers, model dimension , and attention heads, following Thapa et al. (2025) - modest by language-model standards, deliberately so. The thesis is about training recipe, not about scaling the model.
Pretraining objective: contrastive learning
The encoder is trained with InfoNCE-style contrastive objectives. The familiar version, popularized for cross-modal alignment by CLIP (Radford et al., 2021) on image–text pairs and originally introduced by Oord et al. (2018), pulls aligned views of the same example together and pushes unrelated views apart:
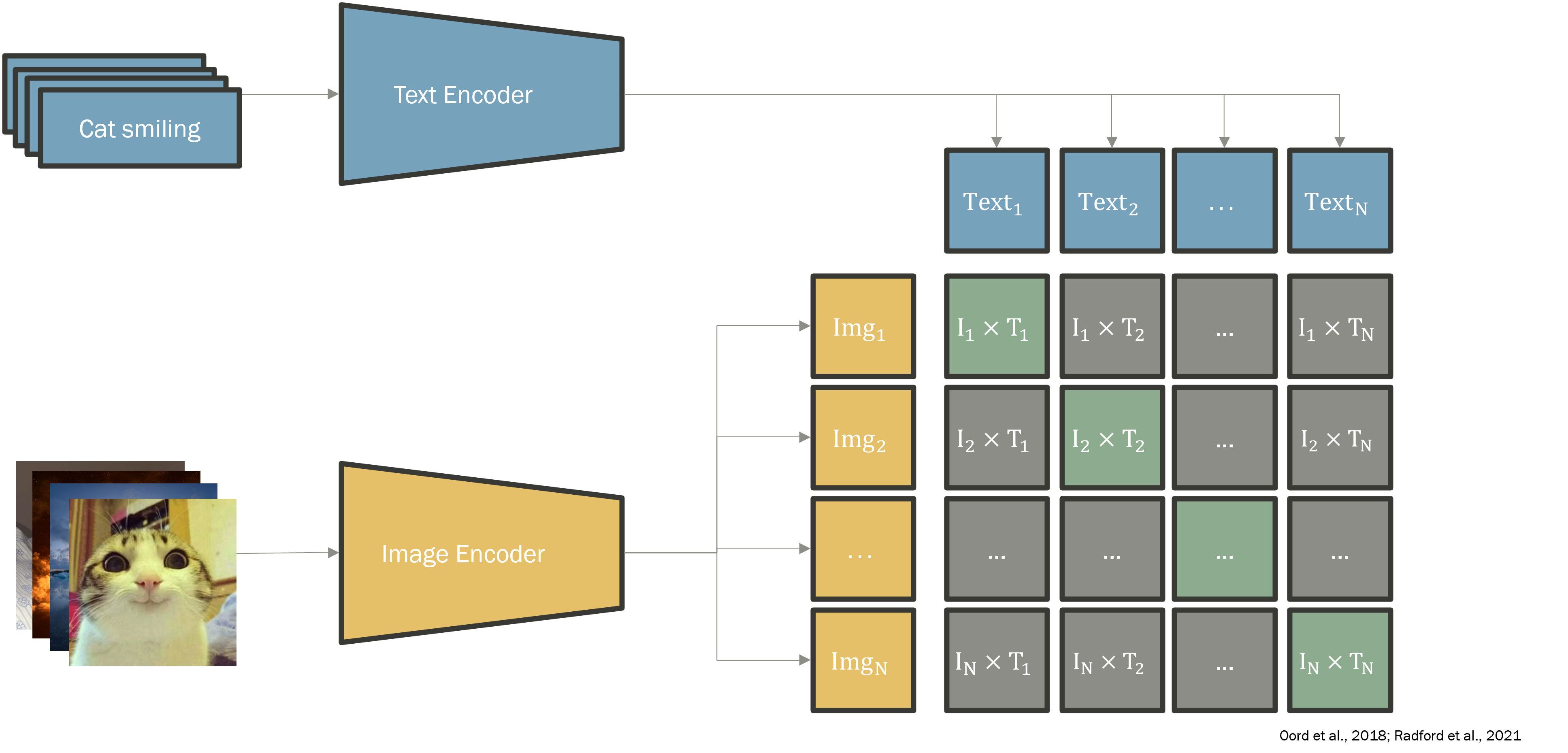
For sample with anchor embedding and positive , with negatives drawn from the rest of the batch:
The PSG-specific variant, Leave-One-Out Contrastive (LOOC) loss from Thapa et al. (2025), exploits the multimodal structure of polysomnography. For each sample, separate encoders produce per-modality embeddings (BAS, ECG, RESP, …); the anchor is one modality's embedding, the positive is the mean of the other modalities' embeddings for the same epoch, and negatives are all other samples in the batch:
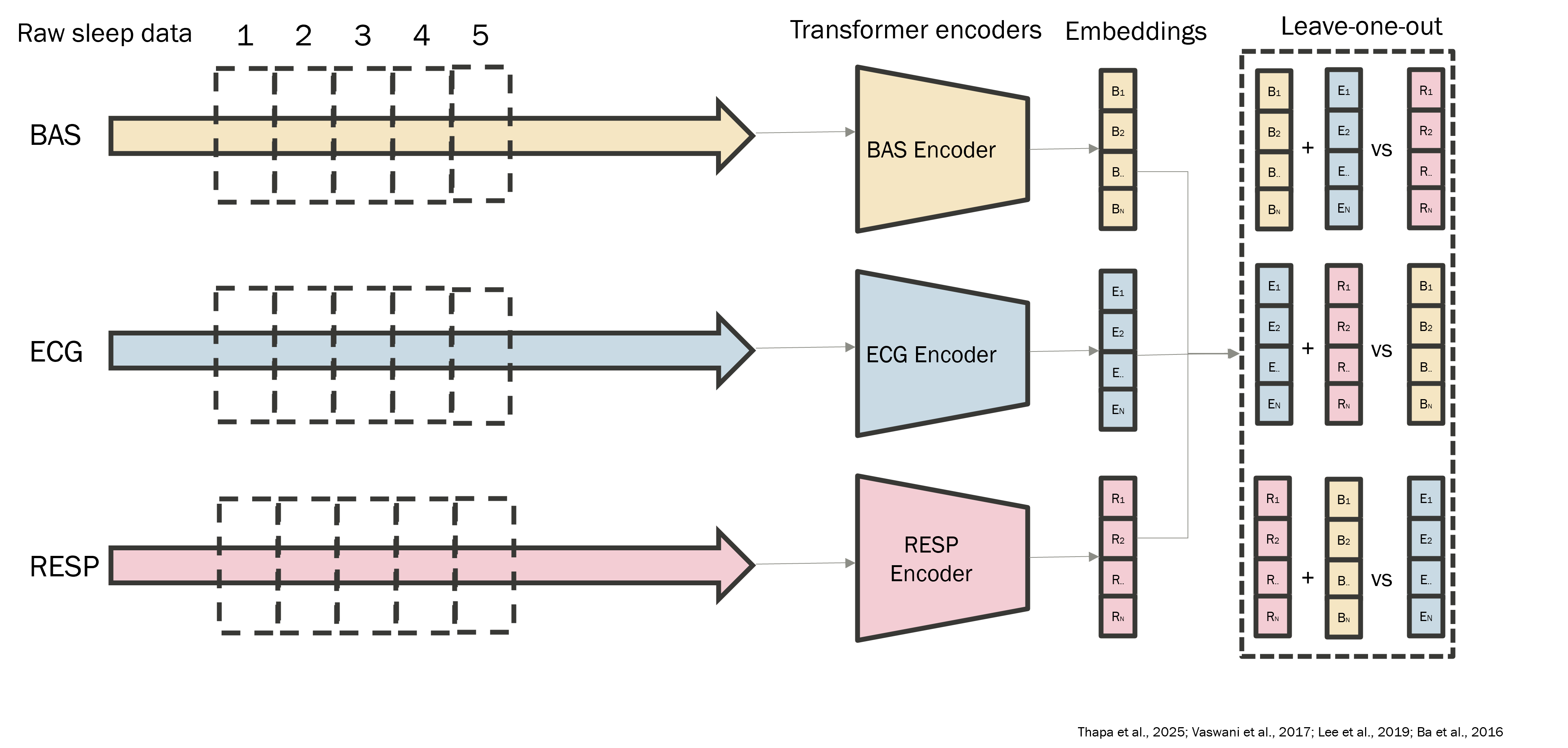
Formally, the leave-one-out positive for modality and sample is:
LOOC then applies InfoNCE with as the anchor and as its positive. Intuitively, the encoder is pushed to learn a representation where each modality's view of an epoch is close to a summary of the other modalities of the same epoch - encouraging cross-modal consistency. Modality dropout randomly hides channels during training to make the encoder robust to missing inputs.
LOOC has a structural limitation: it requires at least three modalities per epoch. Cohorts that only provide BAS (or otherwise lack two modality groups) can't form a LOOC loss at all. To rescue those cohorts, the thesis adds an auxiliary SimCLR-style augmentation loss (Chen et al., 2020) that creates two stochastic views of the same patch (small additive noise, mild amplitude scaling, slight temporal jitter) and applies InfoNCE between them. The combined objective lets single-modality cohorts contribute gradient signal.
Downstream heads
- ·Sleep staging: a bidirectional LSTM (hidden size per direction) over the sequence of epoch embeddings , followed by a linear head over 5 AASM stages. Trained with class-weighted cross-entropy or focal loss.
- ·Apnea detection: a Transformer head producing per-token (4-class respiratory state, 3-class apnea type) and night-level (binary AHI ≥ 15, severity) outputs.
In both cases the foundation encoder is frozen during downstream training - the cheap, label-efficient setup that makes foundation models practical.
Class imbalance and focal loss
Sleep staging is severely imbalanced (N1 is ~5% of recording time). The thesis compares class-weighted cross-entropy against focal loss (Lin et al., 2017), defined as:
The term down-weights well-classified examples and concentrates gradient on hard, misclassified ones.
Data
Pretraining draws from ten public cohorts spanning home and laboratory recordings, community samples and clinical populations:
| Cohort | Type | #Subjects | Hours | Notes |
|---|---|---|---|---|
| MrOS | Community, older men | 2,907 | 31,711 | Largest contributor |
| MESA | Multi-ethnic community | 2,056 | 21,745 | Home PSG |
| WSC | Longitudinal, in-lab | 2,570 | 20,520 | Rich montage |
| STAGES | Multi-site clinical | 1,914 | 15,165 | Adolescents + adults |
| MNC | Multi-site clinical | 1,438 | 13,401 | Broad disorder spectrum |
| CFS | Family-based, OSA | 730 | 7,219 | Children + adults |
| MASS (SS3) | In-lab healthy | 653 | 5,540 | Dense EEG montage |
| Sleep-EDF | Healthy + patients | 394 | 3,849 | Minimal montage |
| HMC | Clinical referral | 302 | 1,144 | No respiratory |
| CAP | Sleep instability | 106 | 993 | Specialized |
| Total | ~13,070 | ~121,287 |
Evaluation cohort (held-out): SHHS (Sleep Heart Health Study), a multi-center community cohort with standardized montage - 5,793 subjects, 48,861 hours, never used during pretraining.
Preprocessing harmonizes signals across cohorts: resample to 128 Hz, channel name normalization via a global inventory, modality grouping into BAS/RESP/EKG/EMG, subject-wise splits to prevent leakage.
Results
RQ1 - Data efficiency of pretraining
The encoder is pretrained on subsampled subject pools of size 1k, 2k, 3k, 5k, 9k, and "BestModel" (full pool). Each scale is run with three random subject samplings to measure seed variance. Downstream is BAS-only sleep staging on SHHS.
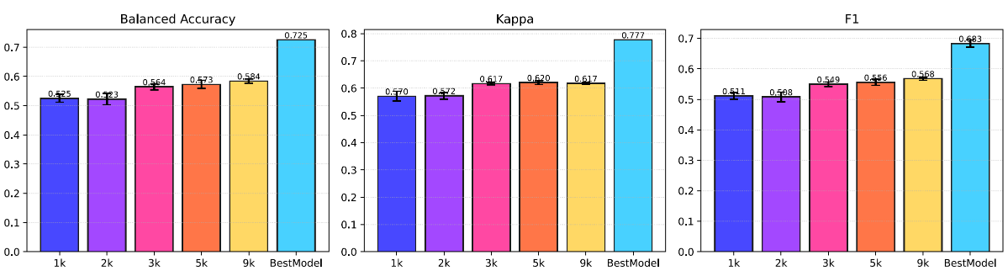
The gain is monotone, with diminishing returns but no abrupt saturation. Seed variance shrinks as the pool grows - large pretraining pools are more stable, not just more accurate. Hypothesis H1a is supported.
To see where the extra pretraining data helps, compare confusion matrices for the smallest and largest pretraining scales:
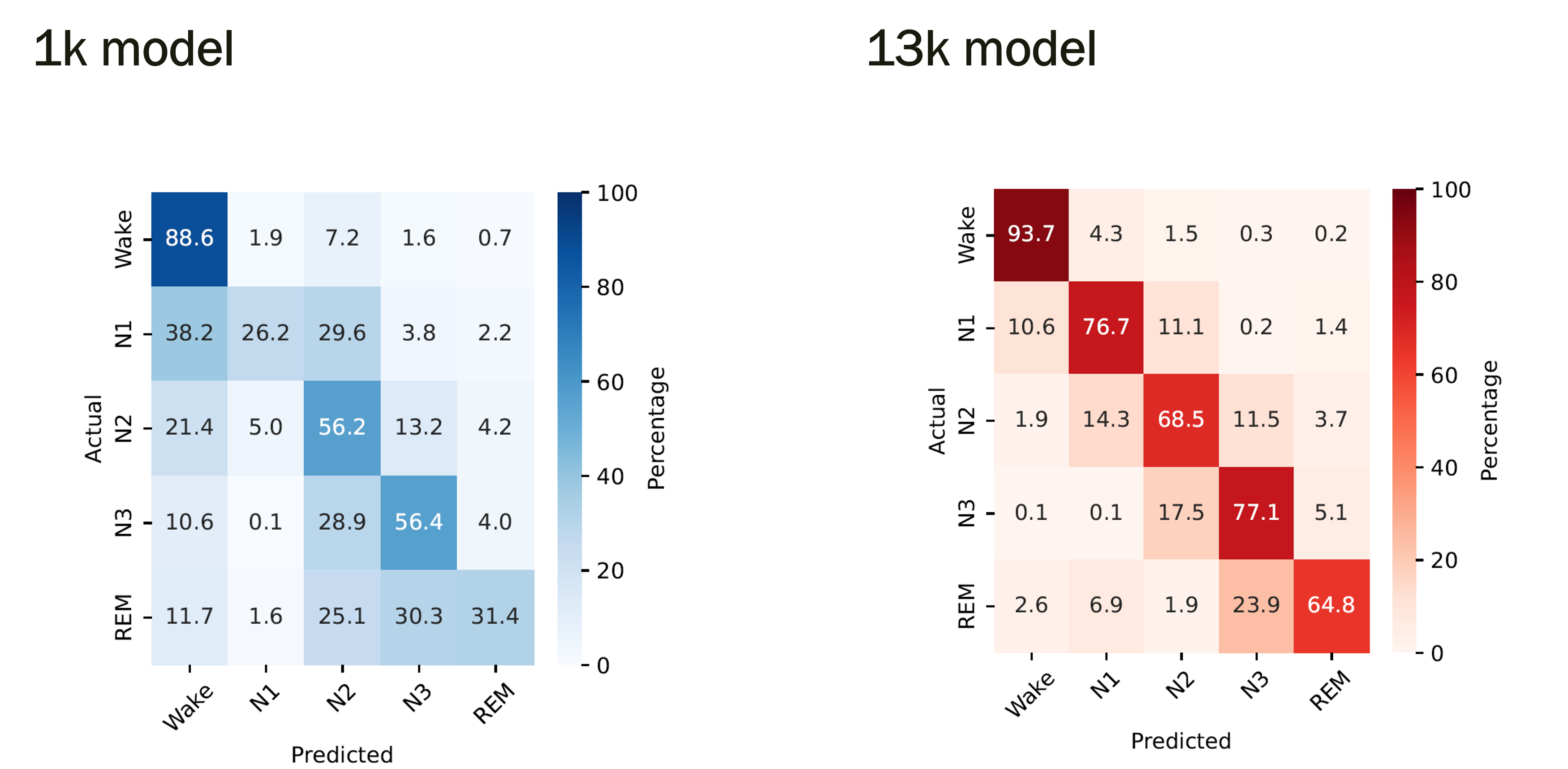
RQ2 - Transfer learning vs. training from scratch
The headline experiment of the thesis. Same downstream architecture (a bidirectional LSTM) trained two ways: (a) on top of frozen BAS-only foundation embeddings, (b) end-to-end from scratch on raw BAS-only PSG. Same input modalities, same hyperparameters, same data - only the encoder differs.
Sleep staging, BAS-only, SHHS held-out:
| Metric | Downstream (frozen FM) | Baseline (from scratch) |
|---|---|---|
| Balanced Accuracy | 76.2% | 37.2% |
| Macro F1 | 66.8% | 31.0% |
| Cohen's κ | 73.8% | 68.75% |
Pretraining more than doubles balanced accuracy and F1 on sleep staging. The confusion matrices make the gain visible per stage:
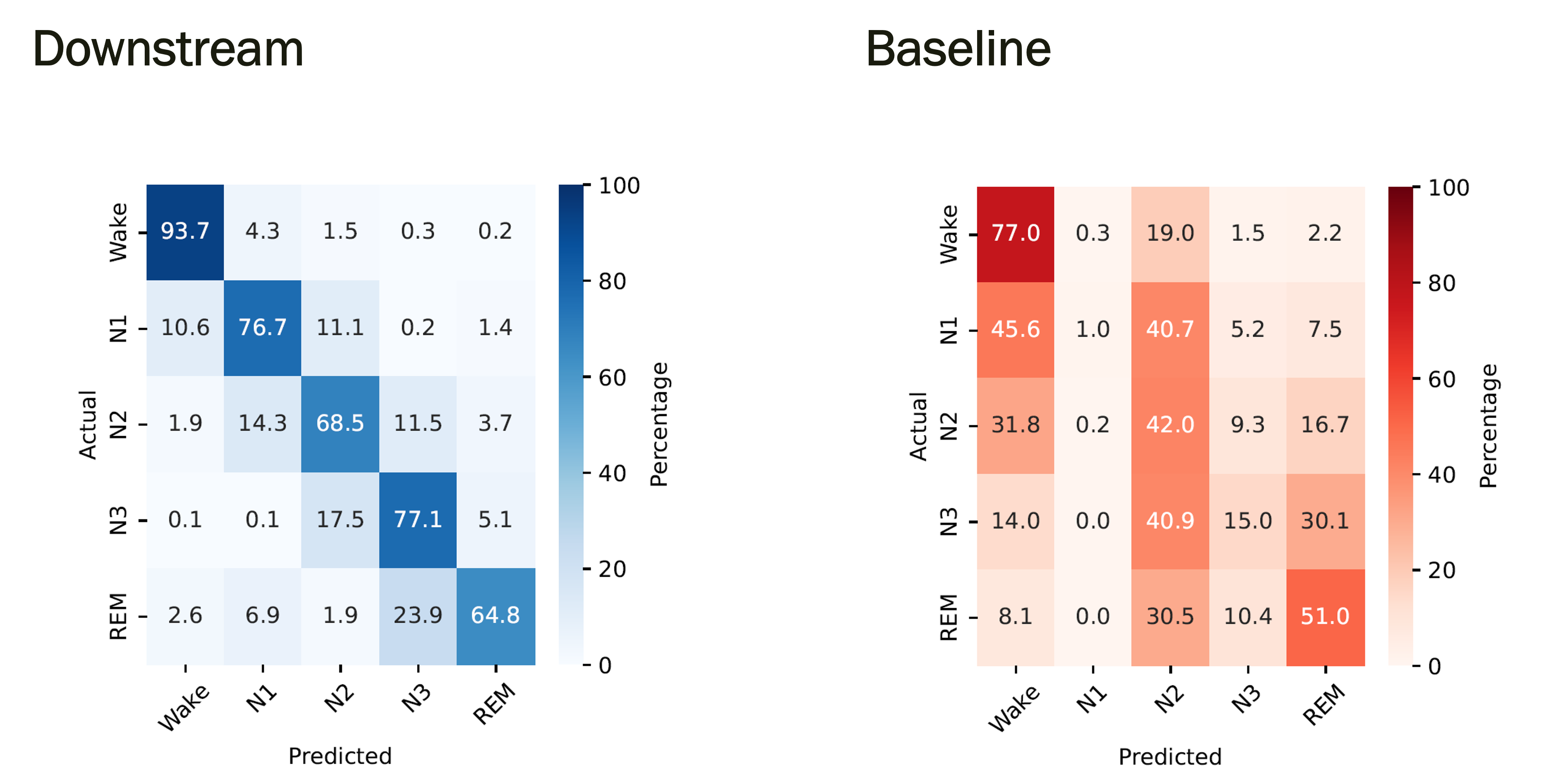
H2a is strongly supported.
Apnea detection, BAS+RESP, SHHS:
| Task | Downstream (frozen FM) | Baseline (from scratch) |
|---|---|---|
| Respiratory event classification | 75.4% | 60.4% |
| Apnea type classification | 81.3% | 62.5% |
| AHI severity classification | 60.4% | 68.75% |
The story is task-dependent: event-level apnea detection clearly benefits from the foundation encoder (substantial gains on respiratory event and apnea type), but the night-level AHI severity classification still favors the scratch baseline. H2b is partially supported - the encoder helps where event-level patterns dominate, less so when the target is the aggregated AHI index. RQ2 overall is therefore partially supported.
RQ3 - Class imbalance and focal loss
Class-weighted cross-entropy vs. focal loss (Lin et al., 2017), both applied to the staging LSTM on frozen embeddings:
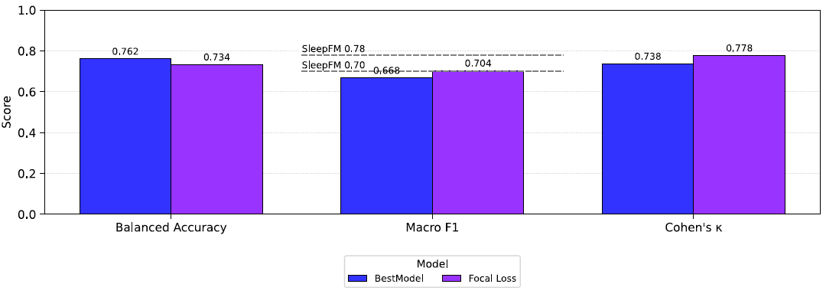
Focal loss trades balanced accuracy for slightly higher F1 and κ. The trade is interpretable: focal loss improves precision on minority stages (N1, REM) at the cost of recall on the same stages. Neither loss dominates - the right choice depends on whether the deployment cares more about per-class balance or about overall agreement.
RQ4 - Modality contributions
Which channels actually matter for which task? Pretraining stays multimodal (BAS + RESP + EKG + EMG); only the downstream modality set varies.
The differences across modality sets are small - about a percentage point on balanced accuracy. BAS (EEG + EOG) already captures most of the staging signal, exactly what the AASM clinical guidelines are built around. Additional modalities give marginal, configuration-dependent gains: EMG slightly helps Cohen's κ, RESP is the only modality that hurts F1 when added alone. H4a is not supported: extra modalities do not substantially improve staging.
For apnea, the picture is completely different:
The single biggest jump is BAS → BAS+RESP, where breathing-disorder accuracy jumps from 60.0% to 75.5%. The confusion matrices show what this looks like - BAS alone misclassifies apnea events as normal breathing, while adding respiratory channels recovers the apnea/hypopnea recall:
| Modalities | Breathing disorder BA | Apnea type BA | AHI severity BA |
|---|---|---|---|
| BAS | 60.0 | 57.6 | 52.3 |
| RESP | 74.8 | 80.6 | 58.3 |
| BAS + RESP | 75.5 | 81.8 | 60.4 |
| BAS + EMG | 60.7 | 55.6 | 54.2 |
| BAS + EKG | 68.8 | 63.8 | 54.2 |
| BAS + RESP + EMG | 75.9 | 84.5 | 60.5 |
| BAS + RESP + EKG | 74.2 | 83.2 | 60.4 |
| BAS + EMG + EKG | 63.5 | 65.3 | 56.3 |
| BAS + RESP + EMG + EKG | 75.4 | 84.5 | 61.1 |
H4b is supported. RQ4 overall is partially supported: modality value is task-dependent - small for staging, large for apnea.
RQ5 - LOOC vs. LOOC + SimCLR
The encoder pretrained with LOOC alone is compared against an encoder pretrained with LOOC + an auxiliary SimCLR augmentation term. Same architecture, same data pool, same compute. Downstream sleep staging on SHHS:
| Metric | LOOC | LOOC + SimCLR |
|---|---|---|
| Balanced Accuracy | 76.2% | 75.0% |
| Macro F1 | 66.8% | 65.2% |
| Cohen's κ | 73.8% | 74.0% |
LOOC alone slightly outperforms LOOC + SimCLR on the primary metrics; the difference is small (≤1.6 pp) but consistent enough that SimCLR doesn't deliver the hoped-for improvement on the held-out cohort. H5a is not supported on staging accuracy.
The practical takeaway is more nuanced than the table suggests: SimCLR's value isn't accuracy on SHHS - it's that it lets single-modality cohorts (BAS-only datasets like HMC, CAP) contribute to pretraining at all. The LOOC objective structurally requires at least three modalities per epoch, so those cohorts would otherwise be discarded. With the largest cohorts already LOOC-compatible, the extra data from these smaller cohorts is too marginal to move the needle on SHHS specifically. RQ5 is therefore partially supported: the modality-aware objective enables more heterogeneous pretraining, even if downstream metrics don't reflect a direct win.
Challenges
Pretraining-pool imbalance. Two cohorts (MrOS, MESA) contribute ~44% of total recording hours. Without cohort-aware sampling the encoder can implicitly specialize to older adults from community samples. The thesis samples uniformly over subjects and does not reweight at the dataset level - a limitation explicitly called out and a clear lever for future work.
Single-cohort evaluation. All downstream results are on SHHS. The encoder is pretrained on ten cohorts, but generalization claims about other hospitals, age groups, or scoring conventions are indirect. The literature (Alvarez-Estevez & Rijsman, 2021) reports substantial drops when models trained on one cohort are tested on another; the thesis can't fully rule that out for its own encoder.
Modality-set asymmetry. RESP being indispensable for apnea and largely irrelevant for staging means that cohorts without respiratory channels are more useful for one downstream task than the other. The foundation-model framing - "one encoder for all tasks" - has to be tempered by this. The encoder is general; the value of any particular pretraining cohort is task-dependent.
The scratch baseline question. RQ2's headline result - pretraining more than doubles balanced accuracy - invites the obvious follow-up: is the scratch model just badly tuned? The thesis is conservative about this, noting in the limitations that systematic baseline tuning is a needed next step. The pretrained gains are large enough that even a 5–10 point improvement in the scratch baseline wouldn't overturn the finding, but it would change its magnitude.
Learnings
The foundation-model framing works for PSG, but the gain is task-dependent. Frozen multimodal pretraining transfers strongly to BAS-only sleep staging (76.2% vs. 37.2% balanced accuracy) and to event-level apnea sub-tasks (75.4% vs. 60.4% on respiratory event classification). The one place it doesn't fully win is night-level AHI severity, where the scratch baseline catches up. The implicit lesson: a "foundation model" is a foundation for the patterns it has learned to recognize. Event-level patterns in physiological signals transfer cleanly; aggregated clinical indices are a noisier target where careful supervised tuning still pays off.
Most of the value comes from the first few thousand subjects. The F1 jump from 1k to 5k pretraining subjects is larger than the jump from 5k to 9k. This argues for cohort diversity - more populations, more montages, more disorders - over cohort size beyond a certain threshold. A practical implication for anyone working in clinical ML on small budgets: collecting more different data beats collecting more similar data.
Set-then-sequence is the right inductive bias for multimodal time series with varying channel sets. The permutation-invariant set encoder makes the model truly channel-agnostic, which is essential when pretraining cohorts have different montages. Trying to engineer a fixed channel order across cohorts is a losing battle.
Contrastive objectives are forgiving. LOOC and LOOC+SimCLR produced near-identical downstream metrics on the target cohort. The contrastive family matters less than the data, the architecture, and the downstream head design.
Class-imbalance handling is more about trade-offs than wins. Neither class-weighted CE nor focal loss strictly dominated. The "right" loss depends on which clinical error you care about - confusing N2 with N3 has different implications than confusing N1 with Wake. Lossless choices don't exist; transparency about the trade-off is what matters.
Future Improvements
- ·Masked-reconstruction pretraining. The thesis only explores contrastive objectives. Masked autoencoding (He et al., 2022) has shown strong results on EEG and time series in the recent literature and would likely produce more interpretable, finer-grained representations of waveform structure.
- ·Cohort-aware sampling. Explicit reweighting at the dataset level, or over-sampling under-represented cohorts during pretraining batches.
- ·Cross-cohort downstream evaluation. Test the same encoder on HMC, Sleep-EDF, or MASS as held-out targets rather than only as pretraining sources, to measure true generalization rather than within-source transfer.
- ·Broader downstream task portfolio. Arousal detection, periodic limb movement detection, insomnia phenotyping, and long-term cardiovascular outcome prediction - all candidates for stress-testing a single PSG foundation model.
- ·Lightweight downstream heads. All staging experiments use a single bidirectional LSTM head, all apnea experiments a single Transformer head. Systematic head-architecture sweeps would clarify how much of the residual gap to prior work comes from the head versus the encoder.
References
Key papers cited throughout. Architecture and contrastive setup follow Thapa et al. (2025); Transformer encoder blocks follow Vaswani et al. (2017); permutation-invariant set pooling follows Lee et al. (2019); layer normalization follows Ba et al. (2016); InfoNCE follows Oord et al. (2018); CLIP-style cross-modal alignment follows Radford et al. (2021); SimCLR follows Chen et al. (2020); focal loss follows Lin et al. (2017); cross-database PSG generalization analysis follows Alvarez-Estevez & Rijsman (2021).
📄 Read the full thesis (PDF) - 108 pages, including the complete derivation of the architecture, all hyperparameters, per-cohort channel tables, confusion matrices for every RQ, and a more detailed discussion of cross-dataset challenges.