
Movie Chatbot - Graph-Grounded QA with Local LLMs
Overview
A movie chatbot that answers factual, recommendation, multimedia, and crowd-sourcing questions about films, built under two hard constraints: no external AI APIs (no OpenAI, Anthropic, Mistral - only locally-runnable models) and all factual information must come from a provided RDF knowledge graph rather than the LLM's parametric knowledge. Co-authored with Fabien Morgan.
The system handles five question types:
| Type | Example | Source of truth |
|---|---|---|
| Factual | "Who directed Good Will Hunting?" | SPARQL on graph |
| Recommendation | "I like The Lion King, Pocahontas, Beauty and the Beast - recommend something" | Movie embeddings (cosine similarity on mean vector) |
| Multimedia | "Show me a picture of Halle Berry" | SPARQL on graph + IMDb image IDs |
| Crowd-sourcing | "What is the box office of The Princess and the Frog?" | Crowd dataset + Fleiss' κ when graph is silent |
| Embedding-enhanced | Any factual question | Graph answer + embedding context |
Motivation
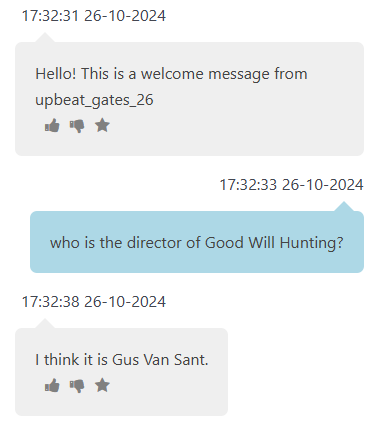
The constraints forced a specific design philosophy: the LLM is never allowed to be the source of facts. An LLM trained on web data might confidently state that Good Will Hunting was directed by Gus Van Sant - and it would happen to be right - but that's parametric memorization, not retrieval. The graph is the only legitimate source, so the LLM's job is reduced to two things: surface-level entity extraction and natural-language wrapping of structured answers.
This is essentially a small RAG system where retrieval is structured (SPARQL) rather than vector-based, with embeddings layered in for fuzzy matching and recommendation.
Technical Approach
Architecture
The system runs as a chatroom agent that listens for messages, classifies them, dispatches to the appropriate handler, and uses a local Llama 3.2 1B model only at the final step to phrase the structured answer in natural language.
The pipeline has four conceptual layers:
- ·
Entity layer - Flair's
SequenceTaggerextracts spans taggedMISC,LOC,ORG(movies tend to be tagged inconsistently across these) andPER(for multimedia/actor questions). A fragment-reassembly step reconstructs multi-token titles like The Masked Gang: Cyprus that NER often splits. - ·
Validation layer - Extracted titles are fuzzy-matched (≥90% similarity) against both the graph and the embedding vocabulary. This is what makes the bot typo-tolerant: "Pricess and the Frog" still resolves correctly.
- ·
Retrieval layer - Either a templated SPARQL query (factual/multimedia) or a nearest-neighbor search in embedding space (recommendation). For recommendations, the mean of the input movies' embeddings is the query vector, and results are filtered to keep only entities of type movie.
- ·
Generation layer - A locally-hosted Llama 3.2 1B model receives the structured result plus a short instruction and produces the user-facing sentence. The model never sees the question alone - it only paraphrases verified data.
Natural language to SPARQL
Rather than have an LLM generate SPARQL (which we tried - see Challenges), queries are built from JSON templates keyed by the question's predicate. The classifier maps trigger words (director, box office, release date, etc.) to a role, then fills the template with the validated movie title.
Example template for "who directed X?":
{
"conditions": [
"?movie rdfs:label \"Good Will Hunting\"@en .",
"?movie wdt:P57 ?person .",
"?person rdfs:label ?personName ."
],
"role": "director",
"select": "?movie ?personName",
"limit": 1
}
This produces a deterministic SPARQL query. A key detail: every template includes a type-constraint clause forcing ?movie to be of type movie, which prevents the bot from returning, say, a director when asked about a similarly-named book.
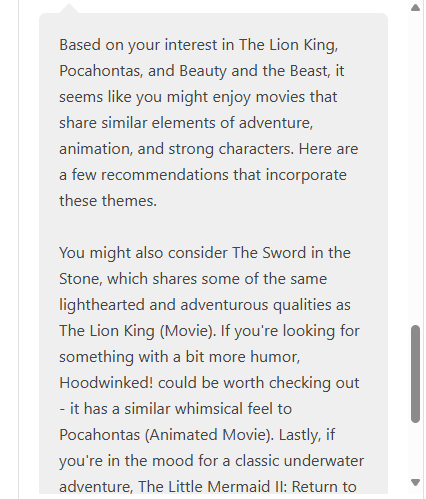
Recommendation via mean-embedding similarity
For "Given that I like A, B, C, recommend something":
The mean-vector trick is crude but works well when the input movies share a coherent theme (all three Disney-animated → Disney-adjacent recommendations like The Sword in the Stone). It fails predictably when the input is thematically scattered.
Multimedia and crowd-sourcing
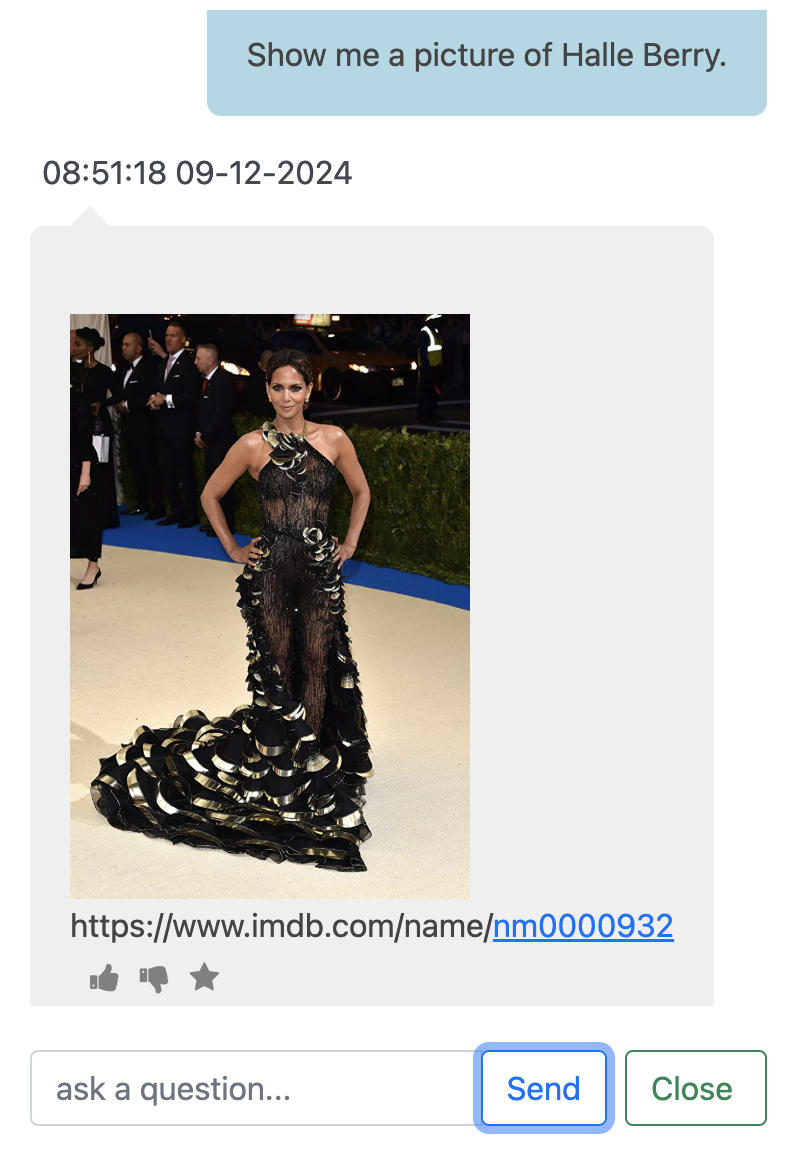
Multimedia questions follow the factual path but use an actor-image template that joins the graph's actor URI to a JSON-side mapping of IMDb image IDs, producing an HTML <img> tag and a clickable IMDb link.
Crowd-sourcing is a fallback: when the graph returns no result for a factual question, the bot checks the crowd dataset, computes Fleiss' κ over the annotators' votes, and surfaces both the answer and the agreement score so the user can judge confidence. Example output: "Based on crowd-sourcing the answer is 267,000,000. Inter-rater agreement: 0.236. Distribution: 2 support, 1 reject."
Challenges
LLM-generated SPARQL didn't work at our scale constraint. We initially wanted a local LLM to generate SPARQL directly from natural language. We tested Falcon 1B and Llama 3.2 3B. Falcon couldn't produce syntactically valid SPARQL at all. Llama 3B could, but was too heavy to run with acceptable latency on the target machine. The rule-based template approach replaced it: less flexible for genuinely novel queries, but far more reliable for the question types we actually needed to support.
NER libraries differ a lot on movie titles. We benchmarked Flair, spaCy, and Stanza on the OLAT example questions. Flair was the most accurate, particularly on titles like Good Will Hunting that don't surface as PER or obvious named entities - Flair consistently tagged movies under MISC, which gave us a reliable signal to filter on.
Title fragmentation. NER routinely split titles with embedded colons, locations, or punctuation. A reconstruction pass that re-merges adjacent entity spans of the same tag class fixed most cases.
Entity-type ambiguity in the graph. A naive SPARQL query for "director of X" can match non-movie entities sharing the title. Every template now includes a type constraint pinning ?movie to the movie class, which made the failure mode "no answer" rather than "wrong answer" - much easier to recover from via the crowd-sourcing fallback.
System Design
The full system is split across modules with clear responsibilities:

Everything is Dockerized for reproducible deployment, and a test suite covers the question-classification and SPARQL-template paths.
Learnings
Templated retrieval beats generative retrieval at small scale. Given a fixed set of question types and a hard latency/memory budget, hand-rolled templates with a strong NER frontend outperformed every attempt at LLM-generated SPARQL we could fit on the machine. The lesson generalizes: when retrieval has structure, exploit the structure - don't ask a 1B-parameter model to rediscover it.
Separate the role of the LLM from the role of the database. The cleanest version of this system uses the LLM strictly as a surface-realization layer. Every fact in the output traces back to a graph triple or a crowd-sourcing tuple. This makes the system auditable in a way that pure RAG-into-LLM pipelines aren't.
Fuzzy matching is doing more work than it looks. A 90%-similarity threshold on both NER outputs and graph/embedding lookup absorbs a surprising fraction of real-world input noise - typos, dropped articles, partial titles - without any model-level robustness work.
Crowd-sourcing with κ as a confidence signal is undervalued. When the graph is silent, returning a crowd answer plus the inter-rater agreement gives the user calibration information that a confident LLM answer never could.
Future Improvements
- ·Caching layer. Frequent entities (top-queried movies, common actors) should hit a precomputed cache for both SPARQL results and embedding neighbors. Response latency is currently dominated by graph traversal on warm queries that have no business hitting the graph twice.
- ·Broader question coverage. The current template set is finite; expanding to comparative queries ("which is longer, X or Y?"), aggregations, and temporal reasoning would require either a richer template DSL or a cautious return to LLM-generated SPARQL - now feasible with smaller, more capable models than were available at the time.
- ·Multilingual support. Flair's German models exist; the graph has multilingual labels. The blocker is the SPARQL templates, which hardcode English label tags (
@en). - ·Better recommendation than mean-embedding. Mean-pooling user preferences is a baseline. Diversification (MMR), per-user calibration, or a small learned head on top of the embeddings would all be straightforward upgrades.